LLM Ops vs Traditional MLOps: Key Differences Explained
Introduction
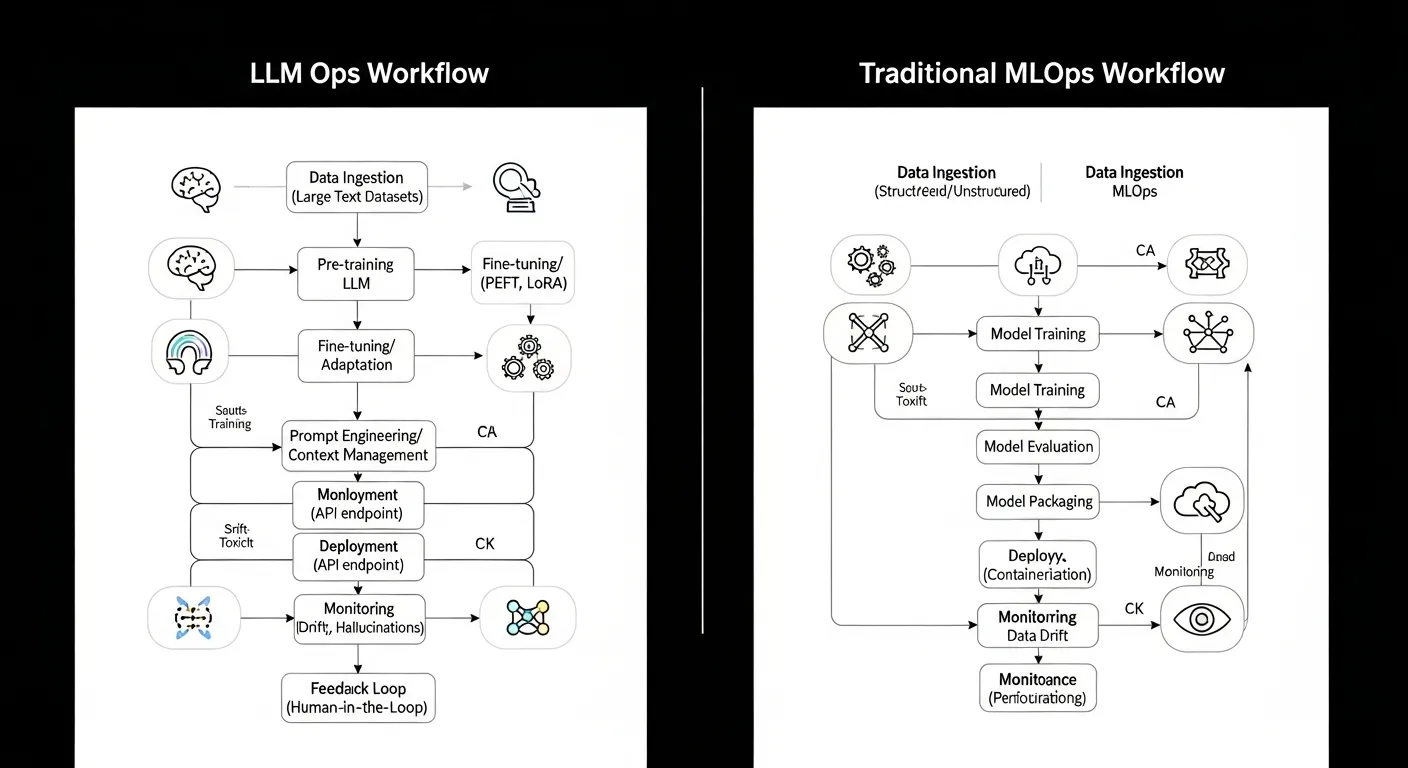
Large language models have reshaped the AI landscape, prompting the rise of LLM Ops as a specialized discipline. While traditional MLOps focuses on data‑centric pipelines and model versioning, LLM Ops addresses the unique challenges of prompt engineering, token management, and real‑time inference at scale.
Core Concept
LLM Ops extends the principles of MLOps to the lifecycle of large language models, emphasizing prompt version control, token flow monitoring, and dynamic scaling of inference hardware to meet variable demand.
Architecture Overview
A typical LLM Ops stack consists of a prompt repository, tokenization service, model runtime, monitoring layer, and automated scaling controller, all orchestrated by workflow engines that integrate with CI/CD pipelines.
Key Components
- Prompt Repository
- Tokenization Service
- LLM Runtime Engine
- Versioned Prompt Store
- Observability and Monitoring Stack
- Auto‑Scaling Controller
How It Works
Developers commit prompts to a versioned store, triggering CI pipelines that validate syntax and performance. The tokenization service converts inputs into model‑ready tokens, which the runtime processes on GPU or specialized inference hardware. Metrics such as latency, token throughput, and hallucination rates feed back into the monitoring stack, enabling automated scaling decisions and alerting.
Use Cases
- Chatbot fine‑tuning pipeline
- Enterprise document search with semantic ranking
- Code generation assistant for developer tools
- Real‑time translation service across multiple languages
Advantages
- Handles massive token throughput with dynamic scaling
- Supports rapid prompt iteration without redeploying the base model
- Enables zero‑downtime model swaps through canary releases
- Provides fine‑grained observability of LLM specific metrics
Limitations
- Higher cost of inference due to GPU or accelerator usage
- Complexity of managing prompt versioning and dependency tracking
- Limited interpretability of LLM outputs compared to traditional models
- Regulatory constraints on data used for in‑context learning
Comparison
Traditional MLOps centers on data pipelines, model training, and static artifact versioning, whereas LLM Ops adds layers for prompt lifecycle, token flow, and inference‑time scaling. MLOps tools excel at batch processing and reproducible training, while LLM Ops focuses on low‑latency serving and continuous prompt optimization.
Performance Considerations
Key performance factors include prompt latency, token per second throughput, GPU memory footprint, and model quantization impact. Optimizing batch sizes, using mixed‑precision inference, and caching frequent prompts can reduce latency and cost.
Security Considerations
LLM Ops must address prompt injection attacks, data leakage through model outputs, and secure handling of proprietary prompts. Role‑based access to the prompt repository, output filtering, and audit logging are essential safeguards.
Future Trends
By 2026 LLM Ops will converge with MLOps into unified AI Ops platforms that automate prompt engineering, support multimodal models, and incorporate self‑healing inference pipelines powered by reinforcement learning from human feedback.
Conclusion
Understanding the distinctions between LLM Ops and traditional MLOps empowers organizations to build robust, scalable, and secure AI solutions that leverage the full potential of large language models while maintaining operational excellence.