Mastering LLM Model Lifecycle Management for Scalable AI
Introduction
Large language models (LLMs) have become the backbone of modern AI applications, but their power comes with complexity. Managing an LLM from conception to retirement requires disciplined processes, the right tooling, and a clear understanding of each phase. This article walks you through the full lifecycle, highlighting best practices, common pitfalls, and emerging trends that will shape the next generation of LLM deployments.
Core Concept
The core concept of LLM lifecycle management is treating a model as a continuously evolving product rather than a one‑time artifact. This mindset drives systematic planning, versioned training, automated deployment pipelines, proactive monitoring, and structured decommissioning, ensuring that the model remains reliable, cost‑effective, and aligned with business goals over time.
Architecture Overview
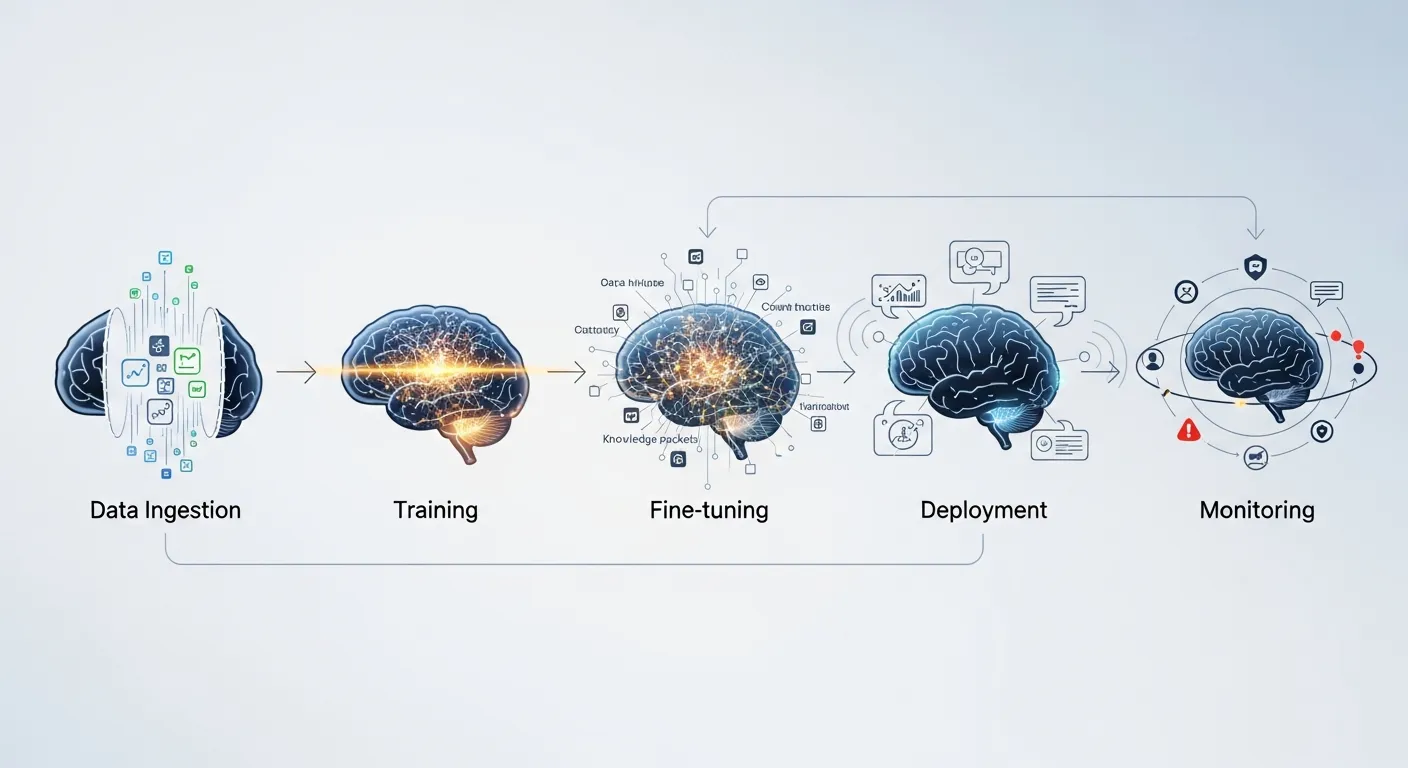
A typical LLM lifecycle architecture consists of four interconnected layers: data ingestion and preprocessing, model training and versioning, serving infrastructure, and observability & governance. Each layer communicates through APIs or event streams, enabling seamless handoffs and feedback loops. Modern platforms often leverage container orchestration, model registries, feature stores, and policy engines to enforce consistency across the lifecycle.
Key Components
- Data pipeline and feature store
- Training compute cluster
- Model registry and version control
- CI/CD pipelines for model artifacts
- Scalable inference serving stack
- Monitoring, logging, and alerting system
- Governance and compliance framework
How It Works
The lifecycle begins with data collection, where raw text, embeddings, and metadata are curated and stored in a feature store. Data quality checks and bias audits are applied before the training stage. In the training phase, experiments are tracked, hyperparameters tuned, and model checkpoints saved to a registry that assigns immutable version identifiers. Once a candidate passes validation, CI/CD pipelines package the model with its runtime dependencies and promote it through staging environments to production. Inference services expose the model via REST or gRPC endpoints, while a sidecar observability stack records latency, token usage, and drift metrics. Feedback from production, such as user interactions or error logs, feeds back into the data pipeline, closing the loop for continuous improvement.
Use Cases
- Customer support chatbots that adapt to new product releases
- Content generation platforms that require brand‑specific tone tuning
- Enterprise search engines that incorporate proprietary documents while preserving data privacy
Advantages
- Improved model reliability through automated testing and monitoring
- Faster time‑to‑value by reusing pipelines and versioned artifacts
- Better compliance with audit trails and governance policies
Limitations
- High operational cost for large compute clusters and storage of multiple model versions
- Complexity of integrating security controls across diverse infrastructure components
Comparison
Traditional ML lifecycle tools focus on smaller models and batch inference, often lacking support for the massive scale and token‑level latency requirements of LLMs. Dedicated LLM platforms add features such as prompt versioning, token‑level monitoring, and specialized hardware acceleration, making them more suitable for generative AI workloads than generic MLOps suites.
Performance Considerations
Performance hinges on hardware selection, model quantization, and request routing. Using mixed‑precision GPUs or custom ASICs can cut inference latency by 30‑50 percent. Sharding large models across multiple nodes enables horizontal scaling but introduces network overhead, so careful placement of attention heads and caching strategies is essential. Autoscaling policies must balance cost with the bursty traffic patterns typical of conversational AI.
Security Considerations
Security must be addressed at data, model, and inference layers. Encrypt data at rest and in transit, enforce role‑based access to the model registry, and apply runtime isolation for inference containers. Prompt injection and model extraction attacks require input sanitization, rate limiting, and watermarking of generated content. Regular penetration testing and compliance scans help maintain a strong security posture.
Future Trends
By 2026 LLM lifecycle platforms will integrate generative AI governance, automated bias mitigation, and self‑healing inference pipelines. Edge deployment of distilled models will enable real‑time AI on devices with limited connectivity. Emerging standards for model provenance and interoperable metadata will simplify cross‑vendor collaborations, while AI‑driven MLOps agents will recommend optimal hyperparameters and resource allocations based on historical performance data.
Conclusion
Effective LLM lifecycle management transforms powerful language models into reliable, secure, and continuously improving AI products. By adopting a structured architecture, leveraging automated pipelines, and prioritizing observability and governance, organizations can unlock the full potential of LLMs while mitigating risks and controlling costs. The future promises even tighter integration of AI governance, edge capabilities, and self‑optimizing operations, making lifecycle management an essential competency for any AI‑first enterprise.